|
Getting your Trinity Audio player ready…
|
🧱 STEP 1 — Text becomes tokens (breaking language into pieces)
Plain English:
You type a sentence.
The model does not see words.
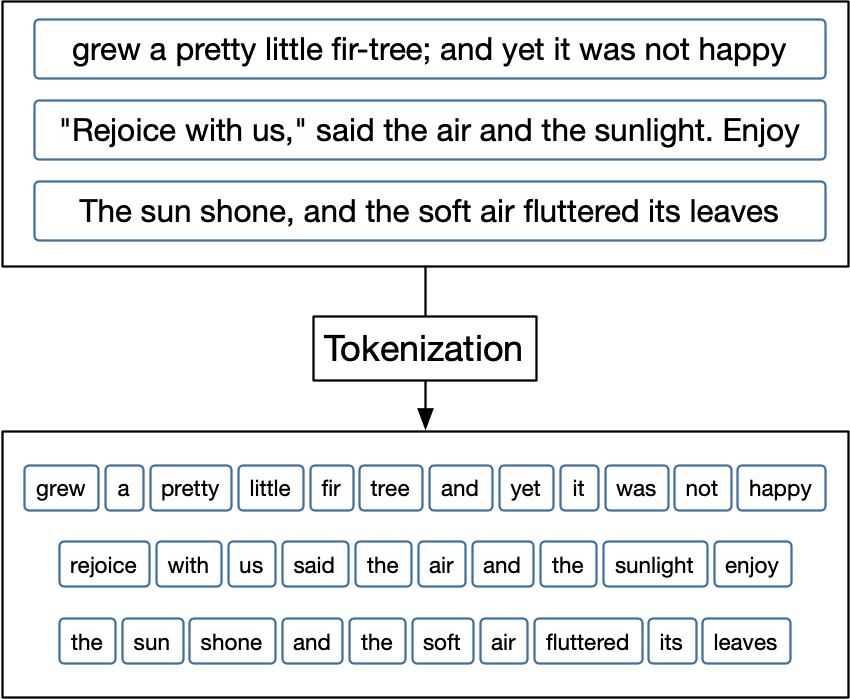
It chops your sentence into tokens — little pieces of language.
Example:
"The storm is coming"
→ ["The", " storm", " is", " coming"]
Each token is just an ID number at first.
No meaning yet — just labels.
Think of this like breaking a melody into individual notes.
🧬 STEP 2 — Tokens become vectors (numbers with shape)



Plain English:
Each token ID is converted into a vector — a long list of numbers.
These numbers:
- Don’t store definitions
- Don’t store facts
- Encode statistical relationships learned from language
Tokens that tend to appear in similar contexts end up with similar vectors.
“Storm,” “rain,” and “wind” live near each other in this space
“Banana” lives far away
This space is what the article calls semantic geometry.
Meaning = position + direction in a very high-dimensional landscape.
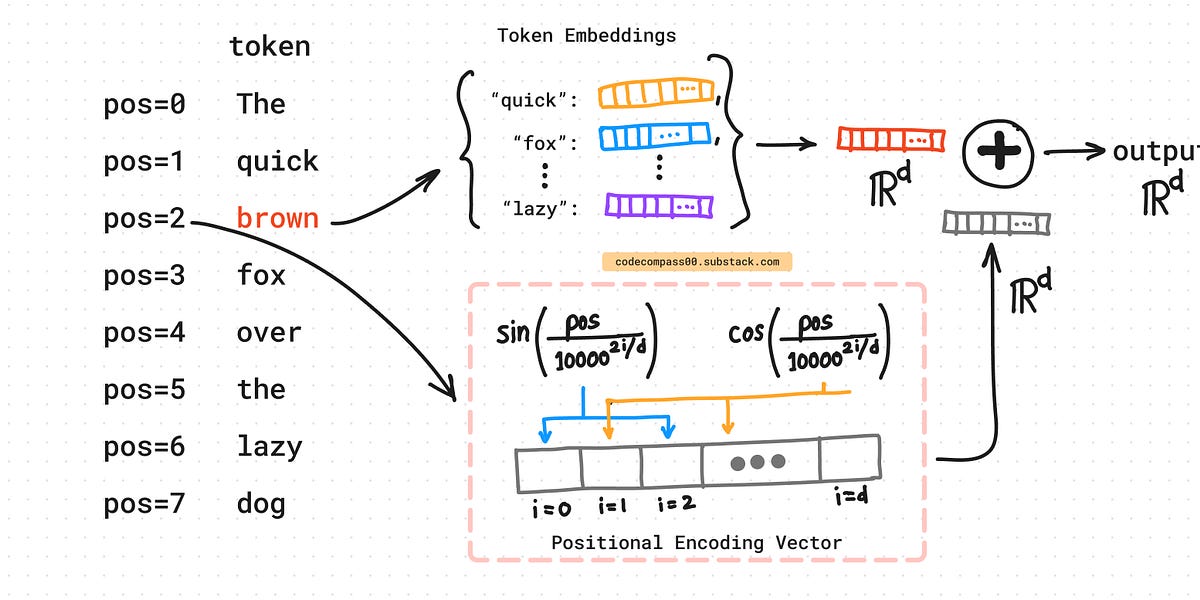
🧭 STEP 3 — Position is added (order matters)

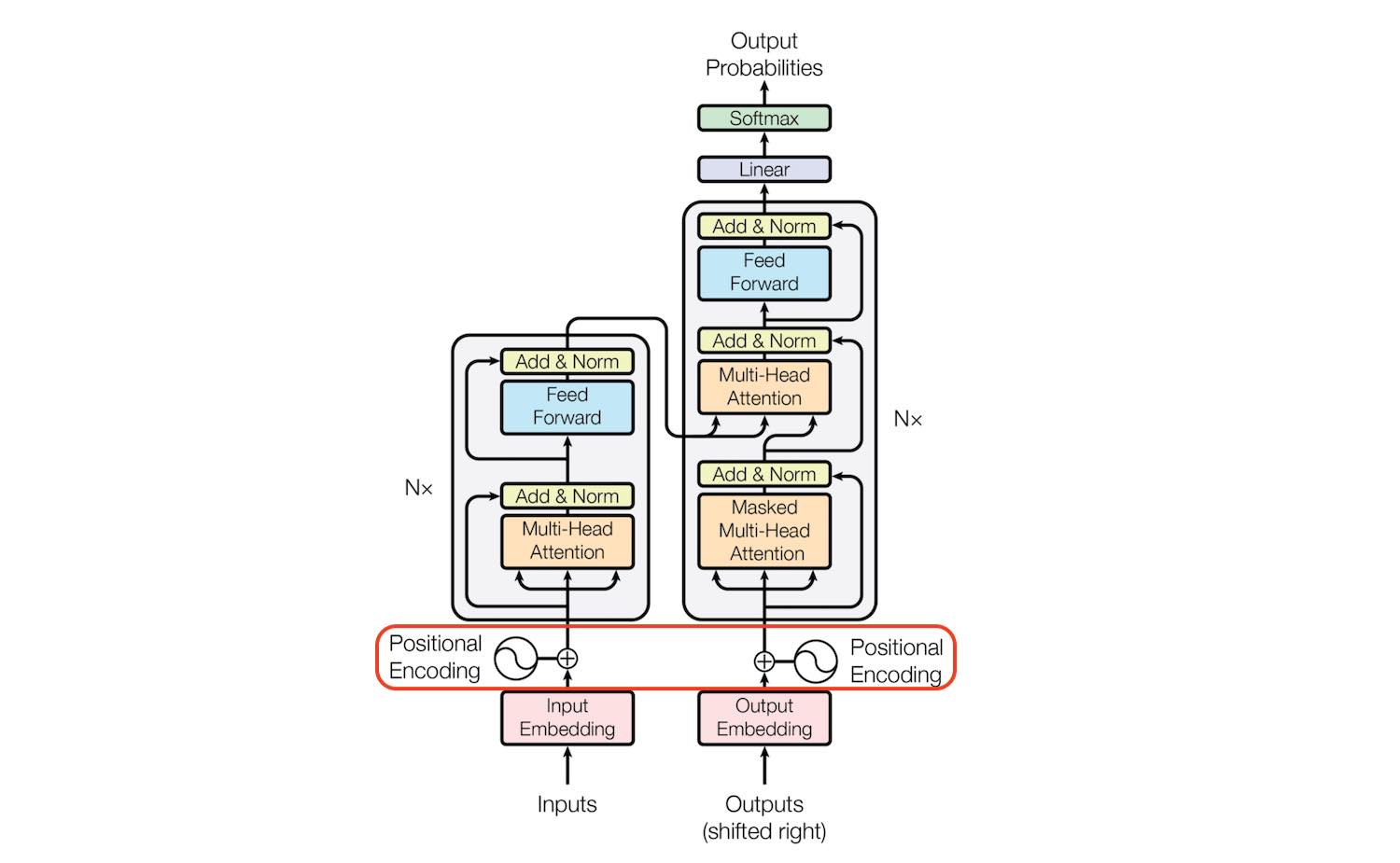
Plain English:
The model now adds position information.
“The storm” ≠ “storm the”
Same words, different order → different meaning.
So the token vector is gently nudged to say:
- Where am I in the sentence?
Think of this like adding timestamps to musical notes.
🌊 STEP 4 — Self-attention: the token looks around
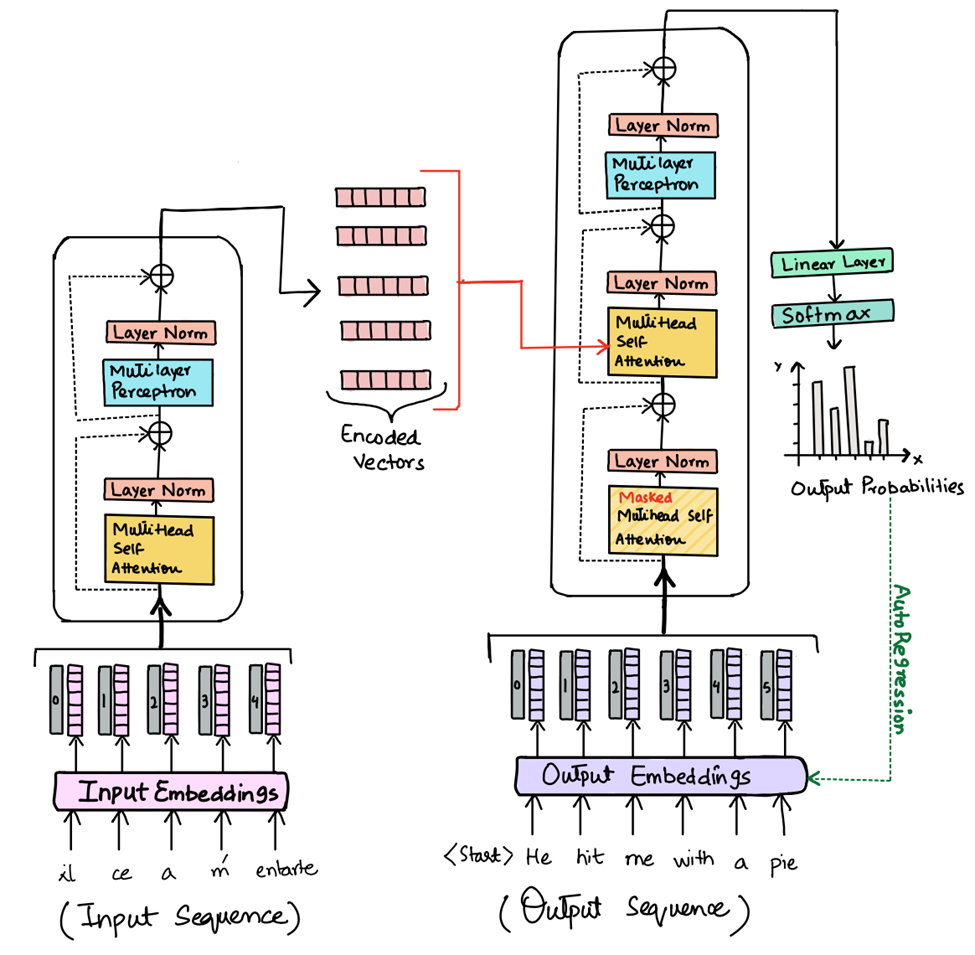


Plain English:
Now the real magic starts.
Each token asks:
“Which other tokens matter most to me right now?”
This is self-attention.
Your token:
- Compares itself to every earlier token
- Measures alignment (similar direction = relevance)
- Turns those alignments into probabilities
Tokens that matter more:
- Pull harder on the current token
- Influence its meaning more
The token is not reading words —
it’s feeling gravitational pulls in semantic space.
🏄 STEP 5 — “Surfing” the semantic geometry


Plain English:
Layer by layer, the token:
- Gets nudged
- Bent
- Rotated
- Stretched
Each transformer layer reshapes the token slightly.
By the end:
- The token no longer represents a word
- It represents “what this word means here, now, in this context”
This is why the article says the token surfs the geometry.
The weights are the waves.
The token is the surfer.
🧪 STEP 6 — Statistics decide the next word
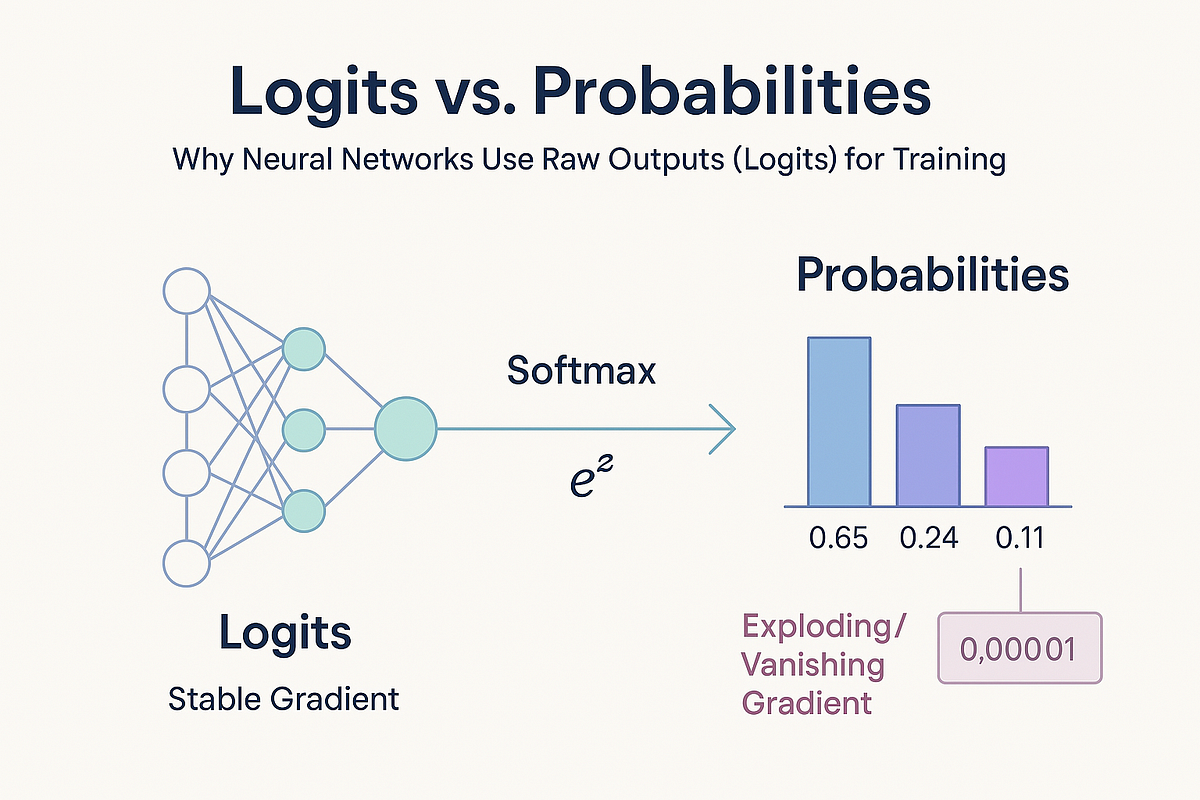
Plain English:
At the final layer, the token’s vector is compared against every possible next token.
Each comparison produces a score.
Those scores become probabilities:
- 42% → “coming”
- 31% → “approaching”
- 5% → “intensifying”
- …
The model either:
- Picks the highest probability
- Or samples (for creativity)
No certainty.
No understanding.
Just statistical inevitability shaped by geometry.
🔁 STEP 7 — The loop continues

Plain English:
The chosen token is appended to the sentence.
Then the entire process repeats.
One token at a time.
Each new token reshapes the geometry for the next.
Language emerges as a controlled statistical cascade.
🧠 THE CORE IDEA (in one paragraph)
Your article explains that an LLM does not think in words and does not store meaning.
Instead:
- Meaning is geometry
- Context is vector alignment
- Understanding is probability flowing through trained structure
A token doesn’t “know” anything.
It simply moves through a landscape sculpted by millions of examples of human language — and lands where language most often goes next.
🔚 FINAL METAPHOR (no math)
A large language model is not a library.
It is not a brain.
It is a wind-shaped desert of meaning.Each token is a grain of sand.
Each prompt is a gust.And text emerges where the dunes naturally form.
Leave a Reply