|
Getting your Trinity Audio player ready…
|
Great — let’s do this very concretely.
From Token Floods to Meaning Islands: A Concrete Latent-Space Architecture

The Toy Prompt (small but realistic)
“Explain why leaves change color in autumn, focusing on chlorophyll breakdown and environmental triggers.”
Tokenized length (approx): 24 tokens
For real models, imagine 2048 tokens — the scaling behavior is what matters.
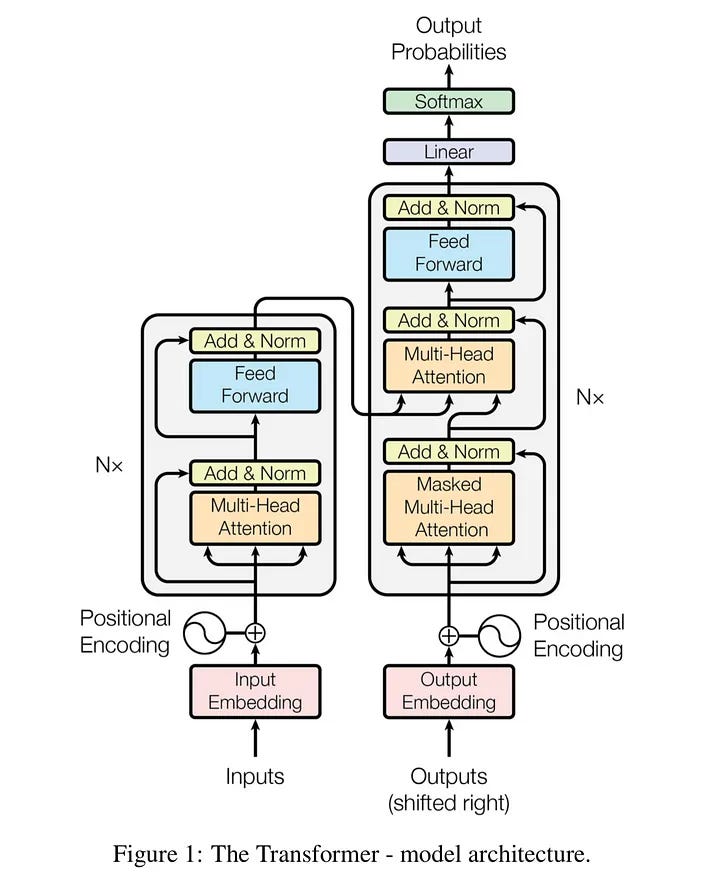
PART 1 — CURRENT ARCHITECTURE (WHAT HAPPENS TODAY)
Step 1: Tokenization
The prompt becomes something like:
[Explain] [why] [leaves] [change] [color] [in] [autumn] [,]
[focusing] [on] [chlorophyll] [breakdown] [and]
[environmental] [triggers]
→ 24 token embeddings
Each is ~4096 floating-point numbers.
Step 2: Transformer Layers (Repeat 30–80 Times)
For every layer, the model does:
a) Self-Attention
- Every token compares itself to every other token
- Creates a 24 × 24 attention matrix
- Multiplies queries × keys × values
b) MLP Expansion
- Each token is expanded (e.g., 4096 → 16384 → 4096)
- Huge matrix multiplies per token
c) Residual + Normalize
- Minor cost compared to above
⚠️ Key point:
All of this happens for all tokens, at all layers, every time.
Step 3: Meaning Emerges… Temporarily
- Somewhere around layer 12–20, “autumn leaves” becomes coherent
- But the model does not store this
- Next prompt → recompute again
Energy Profile (Simplified)
| Component | Cost Driver |
|---|---|
| Attention | O(N²) token interactions |
| MLP | Massive dense matrix math |
| Memory | Weight + activation movement |
| Reuse | Almost none |
PART 2 — LATENT-PER-SPAN ARCHITECTURE (THE ALTERNATIVE)
Now let’s change one thing:
Instead of reasoning over tokens, we compress tokens into latents first.
Step 1: Tokenization (same as before)
24 tokens → embeddings
So far, identical.
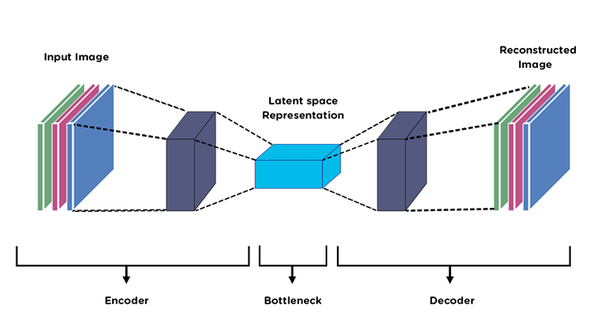
Step 2: Span Encoder → Latent Vectors
We choose:
- Span size = 8 tokens
- 24 tokens → 3 spans
Each span is encoded into one latent vector:
Span 1: "Explain why leaves change"
Span 2: "color in autumn focusing"
Span 3: "on chlorophyll breakdown and environmental triggers"
Each span → latent z₁, z₂, z₃
Each latent:
- Dimensionality: maybe 1024
- Represents meaning, not words
⚠️ Critical difference:
We just reduced 24 computational objects → 3
Step 3: Latent Mixing (Where “Thinking” Happens)
Now we do attention + MLP only over latents:
z₁ ↔ z₂ ↔ z₃
This is where:
- causal reasoning
- abstraction
- integration
happens
But now:
- Attention matrix is 3 × 3
- MLP runs 3 times, not 24
This is where the power savings explode at scale.
What do these latents represent?
Informally:
- z₁: question intent + explanation request
- z₂: seasonal change context
- z₃: biochemical mechanism + triggers
They are semantic islands, not token streams.
Step 4: Optional Persistence (Big Deal)
These latents can be:
- cached
- refined
- reused
- passed to another model
- updated incrementally
This is impossible with token-level ephemeral states.
Step 5: Decoder → Tokens (Speaking Phase)
Only now do we expand back into tokens:
- Decoder reads z₁–z₃
- Generates fluent English
- Surface realization, not reasoning
⚠️ Reasoning happened once per latent, not once per token.
SIDE-BY-SIDE COMPUTE COMPARISON
| Stage | Transformer | Latent-Per-Span |
|---|---|---|
| Objects mixed | 24 tokens | 3 latents |
| Attention size | 24×24 | 3×3 |
| MLP calls | 24 per layer | 3 per layer |
| Meaning reuse | No | Yes |
| Scaling pain | Quadratic | Near-constant |
Now replace 24 tokens with 2048 tokens:
- Transformer: 2048² attention
- Latent model (64 spans): 64² attention
That’s ~1000× less interaction cost.
WHERE MATRIX MATH IS REDUCED (VERY SPECIFICALLY)
Matrix math is not gone — it is front-loaded and amortized.
Heavy math happens:
- Once during span encoding
- Occasionally during latent refinement
Heavy math does NOT happen:
- Per token
- Per decoding step
- Per repeated query
This flips the energy profile.
WHY THIS IS NOT JUST “SUMMARIZATION”
Frank-level insight here:
This is not compression for brevity.
This is compression for persistence.
- Tokens are expressions
- Latents are conceptual coordinates
Once meaning lives in coordinates, computation becomes navigation.
BIOLOGICAL ANALOGY (UNAVOIDABLE)
| Brain | Latent Architecture |
|---|---|
| Sensory neurons | Token embeddings |
| Cortical assemblies | Latent vectors |
| Thought | Latent interaction |
| Speech | Decoder |
Brains do not re-fire every neuron for every syllable.
They activate assemblies.
WHY THIS CHANGES THE ENERGY STORY
Matrix math burns power because it rediscover meaning repeatedly.
Latent architectures:
- discover meaning once
- reuse it many times
- update it sparingly
This is exactly how life reduces energy cost:
Structure first, motion second.
FINAL DISTILLATION
Transformer worldview:
Intelligence = more math, faster
Latent-space worldview:
Intelligence = less math, better geometry
The power savings are not a trick — they are a consequence of respecting meaning as a physical structure, not a transient computation.
Leave a Reply